Quick Start
Quickest Start
You can load this entire example in one click by loading this configuration!
Quick Start
Total cost: ~$25
Let's train a model to generate a funny joke with RL!
The first thing to do is to go to the create training run page.
First, select the "reward function" option:
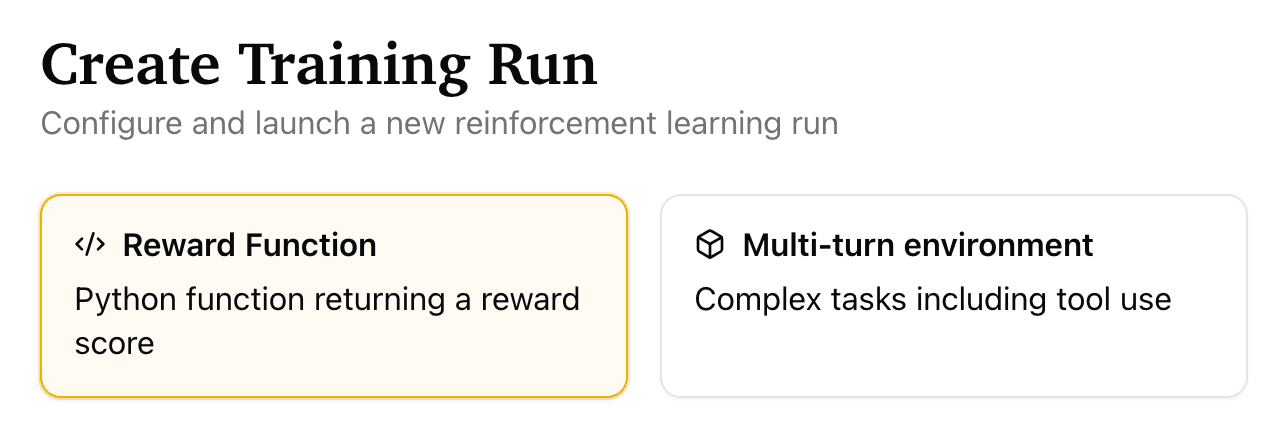
Next, select "Qwen3 4B" as the base model:

It's small enough to train quickly but versatile and intelligent enough to be well-suited for RL!
Now, we need to create a prompt file. A prompt file is a set of JSON object lines, which takes on the following format, e.g.:
{"prompt":[{"role":"system","content":"system prompt"},{"role":"user","content":"user prompt"}],"extra_info":123}
{"prompt":[{"role":"system","content":"another system prompt"},{"role":"user","content":"a second user prompt"}],"extra_info":456}
{"prompt":[{"role":"system","content":"yet another system prompt"},{"role":"user","content":"a third user prompt"}],"extra_info":789}The most important parts of a prompt file is that each line is a JSON, and each JSON should contain a prompt key, which should point to a list of messages in the format {"role": "user", "content": "text"}.
In this example, the prompt can always just be constant, so our JSONL will look something like
{"prompt":[{"role":"system","content":""},{"role":"user","content":"Tell me your funniest joke!"}]}
{"prompt":[{"role":"system","content":""},{"role":"user","content":"Tell me your funniest joke!"}]}
{"prompt":[{"role":"system","content":""},{"role":"user","content":"Tell me your funniest joke!"}]}It's good practice to have the prompts file be at least 50 lines for batch efficiency reasons, so let's make that file slightly longer. If you don't want to do it yourself, you can download it here.
Then, upload it to the prompts file section:
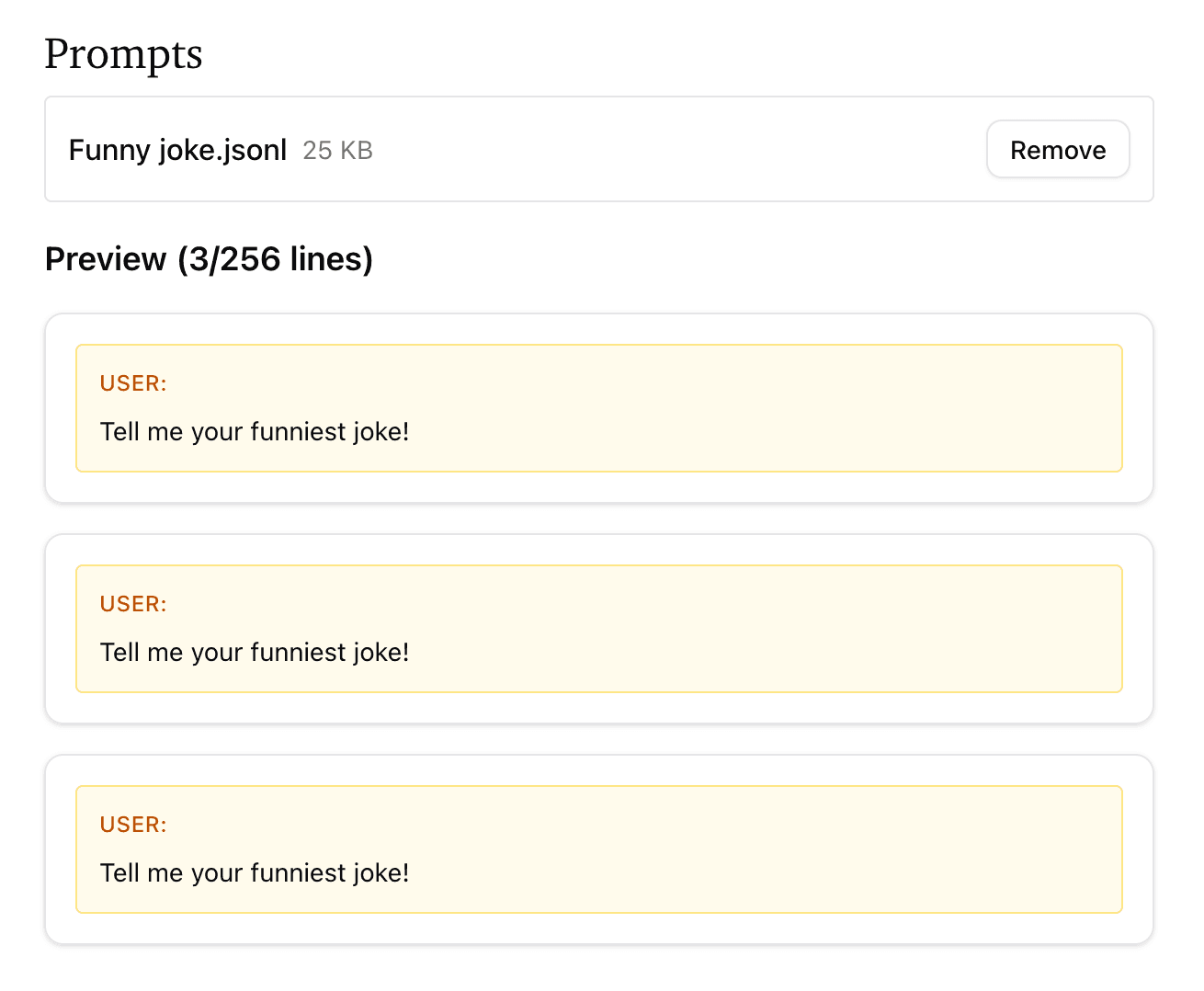
For the reward function, paste the following reward:
from openai import OpenAI
client = OpenAI(api_key=your_key_here)
def reward_fn(completion, **kwargs):
if not completion:
return 0.0
response = client.responses.create(
model="gpt-5-nano",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": f"""Please evaluate this joke, on a scale from 1–10. Make sure to consider how genuinely funny the joke is, as well as its originality, and whether it's interesting; don't reward stale humor. But your north star should be how funny it is!
```
{completion}
```
Please output your final score in <score></score> tags."""
}
]
}
],
text={
"format": {
"type": "text"
},
"verbosity": "low"
},
reasoning={
"effort": "low"
},
tools=[],
store=False,
)
response_text = response.output_text
import re
score_match = re.search(r'<score>(\d+(?:\.\d+)?)</score>', response_text)
if score_match:
score = float(score_match.group(1))
# Return the score directly (1-10 scale)
return score
# If no XML tags found, return 0
return 0.0(You'll need an OpenAI API key for this.)

Now, press "run"! In about 20 minutes, you'll get a model that's ever-so-slightly funnier than before:
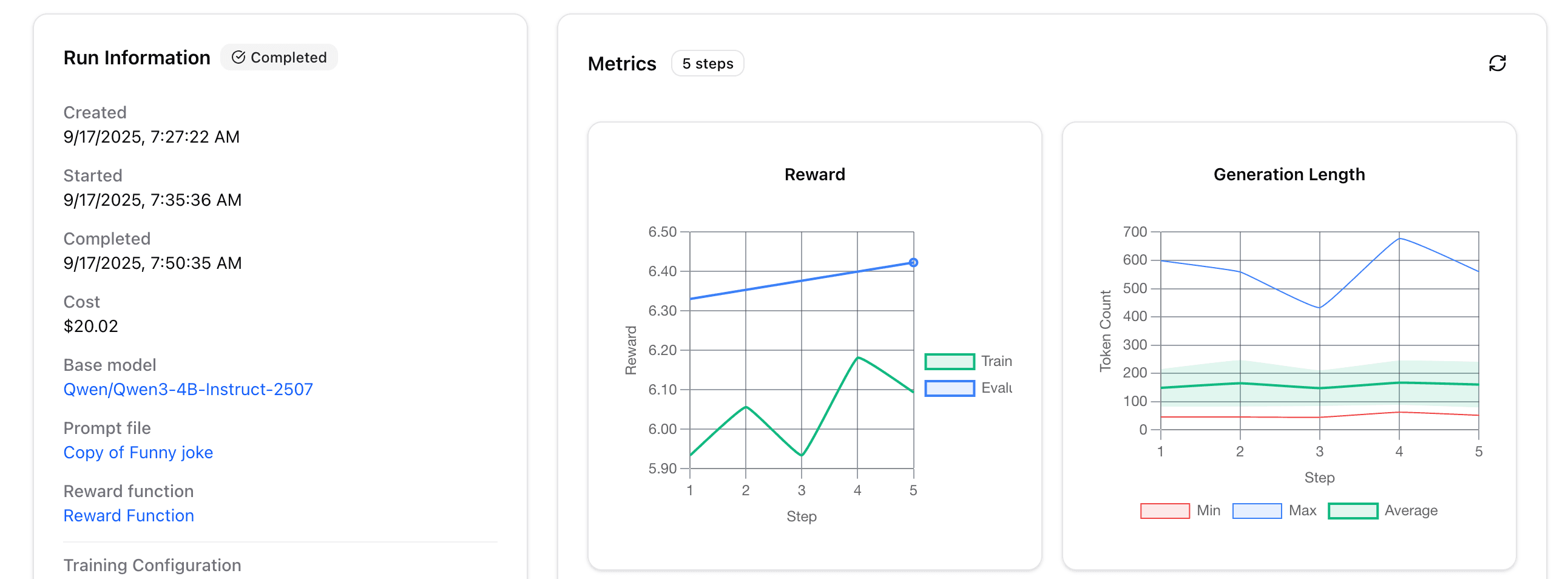
Of course, you could run it for more epochs to make it even funnier! You can also deploy your model for some free slow inference, or email us if you'd like to download your weights.
Happy training!